


Warszawa, ze względu na swoją historię a także znaczenie biznesowe, jest częstym celem biznesowych i turystycznych wypraw. Podróżnicy nierzadko wybierają apartamenty z Airbnb. Czy zastanawiałeś się jak wygląda rynek Airbnb w Warszawie? Jakiej ceny spodziewać się za pobyt (albo jakiej żądać jako gospodarz)? Na te i inne pytania możemy uzyskać odpowiedź z pomocą web scrapingu i podstawowej analizy danych! Pokażemy Ci jak bez wysiłku scrapować Airbnb pomimo, że ta strona używa renderowania JavaScript żeby wyświetlać ogłoszenia i przedstawimy prostą analizę danych.
W tym poście scrapujemy Airbnb w maju 2022. Jeśli Airbnb zmieni na swojej stronie coś z czego korzystamy, kod w tym poście może przestać działać. Jeśli natrafisz na jakiś problem, otwórz issue na GitHubie i zajmiemiy się tym.
Jak pobrać dane? Web scraping na ratunek!
Z pomocą Scraping Fish nie musisz być ekspertem od web scrapingu żeby móc łatwo pobrać dane o noclegach w Warszawie z Airbnb i użyć ich do wizualizacji i wyciągnięcia wartościowych wniosków. Wedle naszej wiedzy Airbnb samo nie publikuje ofert w formie łatwej do analizy (np. w pliku csv albo jako API). Niemniej jednak Airbnb jest publicznie dostępną stroną i można wyszukiwać i przeglądać oferty bez konieczności zalogowania się.
Renderowanie JavaScriptu
Airbnb nie działa bez JavaScriptu. Możesz spróbować uruchomić Airbnb z wyłączonym w swojej przeglądarce JavaScriptem - nie zobaczysz żadnych danych. Oznacza to, że scrapowanie oparte o zwykłe requesty HTTP (np. używanie po prostu bibliotek requests i BeautifulSoup w pythonie) tutaj nie wystarczy - musimy jakoś renderować JavaScript.
Użyjemy naszego API Scraping Fish, które renderowanie JS ma wbudowane. Zamiast wysyłać requesty bezpośrednio do Airbnb, przepuścimy je przez API Scraping Fish i to API załatwi za nas wszystkie problemy (m.in. renderowanie JS). Jedyne co musimy zrobić to dodać prefix do każdego url zgodnie z następującym kodem:
API_KEY = "your API key"
# Nie zapomnij ustawić render_js=true - bez tego nie zadziała
url_prefix = f"https://scraping.narf.ai/api/v1/?render_js=true&api_key={API_KEY}&url="
Jeśli chcesz wypróbować kod samodzielnie będziesz potrzebować klucza API Scraping Fish. Możesz kupić najmniejszą paczkę requestów już za 8 złotych (+VAT).
Scrapowanie i Ekstrakcja danych
Przy przygotowywaniu zapytania musimy mieć na uwadze dwie rzeczy:
- Dla danego query Airbnb listuje 300 ofert - wszystkich ofert w przypadku Warszawy jest więcej.
- Żeby poznać cenę za jedną dobę musimy podać przedział dat i niektóre apartamenty w tym dniu mogą być zajęte.
W celu uzyskania dobrej reprezentacji dostępnych ofert będziemy scrapowali strony podając różne daty. Żeby działanie kodu zakończyło się szybko, ograniczymy się do dni pomiędzy 1 czerwca 2022 a 14 października 2022 i będziemy pobierać dane z częstotliwościa 45 dni, tj. pobierzemy dane z 4 dni (01/06/2022, 16/07/2022, 30/08/2022, 14/10/2022). Możesz ustawić przedział i częstotliwość jakkolwiek chcesz, ale miej na uwadze, że żeby mieć gęsto rozłożone dane potrzebe wiele czasu i występuje tu efekt malejących zysków jeśli chodzi o polepszanie wyników.
Podsumowując: wystartujemy z pewnej daty, będziemy zwiększać ją o ustaloną częstotliwość w każdej iteracji, podczas tej iteracji odpytywać Airbnb używając jednego dnia jako przedziału czasu, przejście przez 15 stron wyników (razem 300 ofert) dla każdego dnia, wyciągać informacje o ofertach i dodawać je do kolekcji. Kod poniżej (w dalszej części uzupełnimy niezdefiniowane funkcje, cały kod jest tu):
Zdefiniujmy parametry użyte do pobrania danych, tj. query, przedział czasu i częstotliwość.
query = "Warszawa"
start_date = datetime.date(2022, 6, 1)
end_date = datetime.date(2022, 10, 14)
freq = '45D'
num_guests = 1
Wysokopoziomo ekstrakcja danych jest bardzo prosta:
offers = []
# Użyjemy tqdm żeby wyświetlić postęp
for date in tqdm(pd.date_range(start_date, end_date, freq=freq)):
offers += process_date(checkin_date=date)
Dla każdej daty musimy zescrapować wszystkie 15 stron ofert (20 ofert per strona). Wzorzec url jest następujący:
https://www.airbnb.pl/s/{query}/homes?checkin={checkin}&checkout={checkout}&adults={num_guests}&items_offset={items_offset}
gdzie:
query- w naszym przypadku"Warszawa",checkin- data zameldowania w formacieYYYY-MM-DD,checkout- data wymeldowania - w naszym przypadku zawsze data zameldowania + jeden dzień,num_guests- liczba gości, u nas zawsze 1 żeby wyświetlić możliwie najwięcej ofert,items_offset- offset do paginacji, równy(strone - 1) * 20.
def process_date(checkin_date, num_guests=1):
# we need to pass the dates in YYYY-MM-DD format
checkin = checkin_date.strftime("%Y-%m-%d")
checkout = (checkin_date + datetime.timedelta(days=1)).strftime("%Y-%m-%d")
offers = []
# it's always 15 pages
for page in range(1, 15+1):
items_offset = (page - 1) * 20
url = f"https://www.airbnb.pl/s/{query}/homes?query={query}&checkin={checkin}&checkout={checkout}&adults={num_guests}&items_offset={items_offset}"
# we need to quote the url as we pass to Scraping Fish API because it contains its own query params, more info: https://scrapingfish.com/docs/url-encoding
url = quote_plus(url)
response = requests.get(f"{url_prefix}{url}")
soup = BeautifulSoup(response.content, "html.parser")
# get all the offers - this returns a list of HTML elements containing the information about the offers (you'll usually get 20 of these here)
offers = soup.select("div.cm4lcvy")
for offer in offers:
current_offer = parse_offer(offer)
offers.append(current_offer)
return offers
Fragment offers = soup.select("div.cm4lcvy") może się wydać tajemniczy. Ta linia wyciąga wszystkie elementy HTML zawierające informacje o ofertach używając selectora css (wyciągamy wszystkie div'y z klasą "cm4lcvy"). Nazwę klasy znaleźliśmy z pomocą inspektora przeglądarki. Te elementy będą potem używane w funkcji parse_offer do wyciągnięcia danych, które nas interesują. Będziemy zapisywać:
- id oferty (
id), - cenę dla danego dnia (
price), - dzień zameldowania (
checkin), - typ (pokój, całe miejsce itd.) (
type), - maksymalną liczbę gości (
capacity), - liczbę sypialni (
bedrooms), - liczbę łóżek (
beds), - liczbę łazienek (
bathrooms), - czy jest wi-fi (
wi-fi), - kuchnia (
kitchen), - pralka (
washing machine), - możliwość samodzielnego zameldowania (
self check in).
W tym poście wykorzystamy tylko część tych danych. Poniższa funkcja parsuje i wyciąga te dane. Dodatkowo, mapujemy określenia w liczbie mnogiej do wspólnej wartości używając słownika key_map (możesz zobaczyć jak wygląda w kodzie):
def parse_offer(offer):
offer_id = offer.select("a")[0]['target'].split("listing_")[-1]
offer_price = float(''.join(offer.select("span._tyxjp1")[0].text.split()[:-1]))
offer_type = " ".join(offer.select("div.mj1p6c8")[0].text.split("w:")[0].split())
offer_features = [feature.text for feature in offer.select("span.mp2hv9t")]
current_offer = {
"id": offer_id,
"price": offer_price,
"checkin": checkin,
"type": offer_type,
}
feature_sets = offer.select("div.i1wgresd")
basic_features = [t.text.lower() for t in feature_sets[0].select("span.mp2hv9t")]
other_features = [t.text.lower() for t in feature_sets[1].select("span.mp2hv9t")] if len(feature_sets) > 1 else []
for feature in basic_features:
split = feature.split()
if len(split) > 1:
current_offer[key_map[' '.join(split[1:])]] = split[0]
else:
if split[0].lower() == 'studio':
current_offer['bedrooms'] = 0
current_offer['wi-fi'] = 'wi-fi' in other_features
current_offer['kitchen'] = 'kuchnia' in other_features
current_offer['washing machine'] = 'pralka' in other_features
current_offer['self check in'] = 'samodzielne zameldowanie' in other_features
return current_offer
Świetnie, teraz mamy nasze cenne dane i jesteśmy gotowi na wyciąganie z nich interesujących wniosków!
Podstawowa Eksploracja Danych
Mając dane w pamięci, stwórzmy data frame Pandas i dokonajmy eksploracji. Przy okazji zapiszemy nasze dane do pliku csv i wczytamy jego zawartość, co ma dodatkowy efekt w postaci automatycznej konwersji danych numerycznych na odpowiednie typy.
offers_df = pd.DataFrame(offers)
offers_df.to_csv('./data.csv', sep=';', index=False)
offers_df = pd.read_csv("./data.csv", sep=";")
Czyszczenie danych
Oczyścimy najpierw dane z duplikatów zliczymy je i zliczymy różne typy ofert. Dodatkowo, w ofertach w których jest "współdzielona" łazienka zamienimy ilość na 1.
offers_df = offers_df.drop_duplicates(subset=['id'], keep='last')
print("Number of data points:", len(offers_df))
print(offers_df['type'].value_counts())
offers_df["bathrooms"].replace({"współdzielona": 1}, inplace=True)
Daje nam to:
| Number of data points | 603 |
|-----------------------------------|-----|
| Cały obiekt – apartament | 365 |
| Pokój prywatny | 137 |
| Pokój w hostelu | 14 |
| Cały obiekt – condo | 14 |
| Cały apartament z obsługą | 13 |
| Pokój współdzielony | 13 |
| Cały obiekt – apartament gościnny | 11 |
| Pokój w hotelu butikowym | 8 |
| Cały obiekt – loft | 7 |
| Pokój w apartamencie z obsługą | 6 |
| Pokój hotelowy | 6 |
| Łóżka w hostelu | 3 |
| Cały obiekt – dom | 3 |
| Namiot | 1 |
| Cały obiekt – domek gościnny | 1 |
| Całe miejsce | 1 |
Jak widać jest wiele różnych szczegółowych typów, ale nas bardziej interesują szersze rodzaje stosowane przez Airbnb, tj.: "Całe miejsce", "Pokój prywatny", "Pokój w hotelu" i "Pokój współdzielony". W tym celu dokonamy mapowania szczegółowych typów na ogólne typy stosując offers_df["type"].replace({...}) (szczegóły w kodzie)
Jakie rodzaje ofert są najczęstsze? Ile łóżek spodziewać się dla danego typu?
Możemy teraz narysować histogram, którzy wskaże nam ile znaleźliśmy ofert tych podstawowych typów i przy okazji sprawdźmy ile zazwyczaj łóżek oferowane jest w danym typie:
plt.figure(figsize=(14,8))
ax = sns.histplot(data=offers_df, x="type", shrink=0.9, alpha=0.9, multiple="stack", hue="beds")
for label in ax.get_xticklabels():
label.set_rotation(35)
ax.set(xlabel="Rodzaj miejsca", ylabel="Liczba")
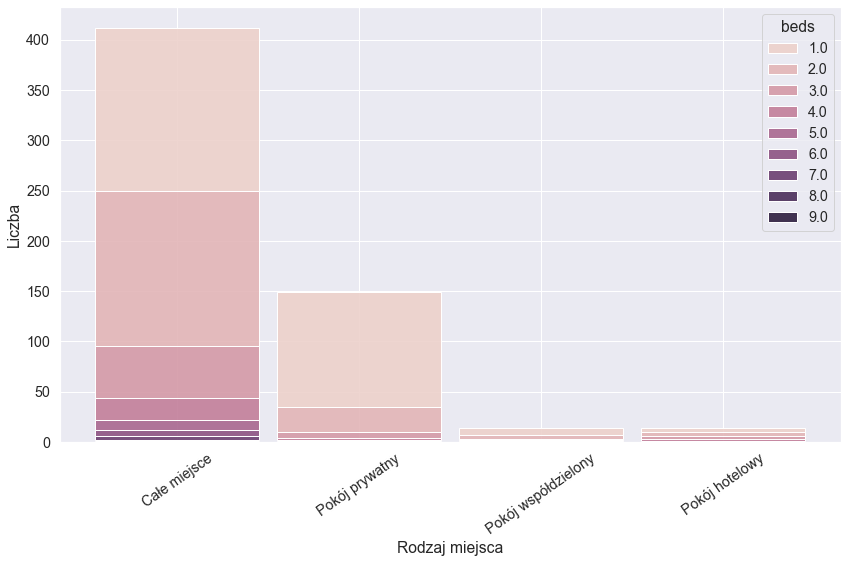
Całe miejsca wyraźne dominują i jednocześnie widać, że większość oferuje jedno lub dwa łóżka.
Cena a maksymalna liczba gości i bardzo drogie oferty
Sprawdzimy teraz jak ceny mają się do maksymalnej liczby gości w oferowanych miejscach. Prawie wszystkie oferty w naszym przypadku mieszczą się w cenie poniżej 2.500 zł, więc wyświetlimy tylko taki przedział:
plt.figure(figsize=(14,8))
ax = sns.stripplot(x="capacity", y="price", hue="type", dodge=True, data=offers_df)
ax.set(ylim=[0, 2500], xlabel="Maksymalna liczba gości", ylabel="Cena")
ax.legend().set_title("Rodzaj miejsca")
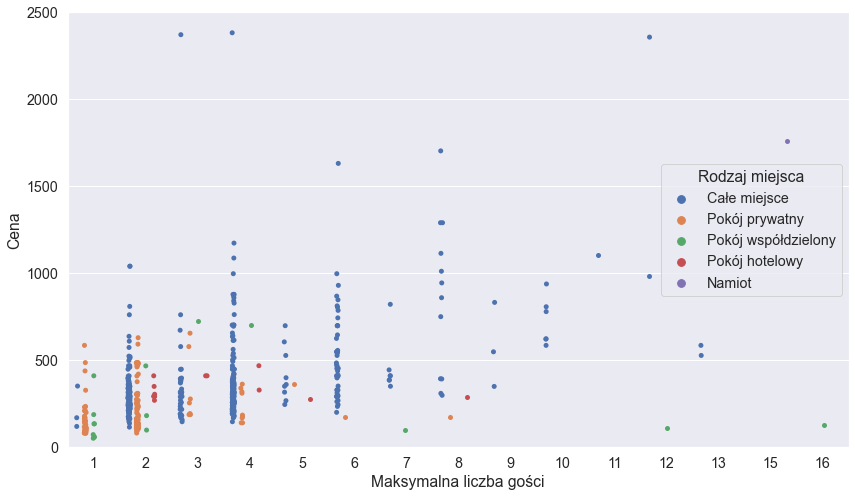
A co z ofertami droższymi od tego progu? Poniżej lista linków do nich:
Poza pierwszym linkiem, termin "przykłady odstające" pasuje do tych ofert idealnie :)
Podsumowanie
Airbnb jest przykładem strony, która nie wyświetla prawie wcale wartościowej treści bez włączonego javascriptu. Funkcjonalność Scraping Fish renderowania javascriptu sprawia, że poradzenie sobie z tym problemem to bułka z masłem.
Ledwie dotknęliśmy zagadnienia eksploracji naszych danych. Żeby zachować prostotę tego posta ograniczyliśmy nasze analizy do stosunkowo małego zbioru danych, żeby zaprezentować co jest możliwe oraz jak łatwo można scrapować strony mocno oparte o javascript. Planujemy jednak pobrać o wiele więcej danych i przeprowadzić znacznie bardziej wnikliwe analizy, więc bądźcie czujni, followujcie nas na Twitterze i sprawdzajcie naszego bloga!
Jeśli też scrapujesz dane i budujesz przy użyciu tej technologii produkty sprawdź API Scraping Fish. Możesz zacząć już za 8 zł + VAT bez żadnych zobowiązań.