Wykonywanie kroków JavaScript na scrapowanej stronie

Miło nam przedstawić nową, wyczekiwaną funkcjonalność - wykonywanie scenariuszy JavaScript! Wielu naszych klientów prosiło o udostępnienie możliwości interakcji ze scrapowaną stroną - klikania przycisków, wypełniania formularzy, wybierania opcji w elemencie <select> itd. Teraz jest to możliwe w API Scraping Fish i to bez umniejszenia naszego celu jakim jest utrzymanie naszego produktu tak prostego w użyciu jak to tylko możliwe.
Dlaczego jest mi to potrzebne?
W pewnych sytuacja podczas web scrapingu możesz chcieć nie tylko wczytać stronę, ale też na przykład wybrać opcję, poczekać aż dane się załadują, kliknąć przycisk, który staje się odblokowany dopiero po wykonaniu jakiejś akcji. A może musisz wypełnić formularz zanim interesujące Cię dane będą dostępne. W każdym z tych przypadków scenariusze JavaScript Ci pomogą!.
Czym jest scenariusz JavaScript?
Scenariusz JavaScript to seria kroków, które są wykonywane po załadowaniu strony jeden po drugim. Możliwe akcje to m.in. kliknięcie elementu wyspecyfikowanego selektorem, poczekanie aż element się pojawi albo wypełnienia pola tekstowego. Pełną listę akcji znajdziesz w dokumentacji. Przykład:
{
"steps": [
{"scroll": 1000},
{"wait_for": "#element-id"},
{"select": {
"selector": "#the-select-element",
"options": ["option1", "option2"]
}},
{"click_and_wait_for_navigation": "#button-id"}
]
}
Scenariusz przekazujesz za pomocą zeknodowanego obiektu JSON jako parametr query.
Przykład prawdziwego zastosowania
W celu szbkiej prezentacji możliwości tej nowej funkcjonalności, zescrapujemy jeden pokój z booking.com. Miej na uwadze, że ten kod działa na dzień publikacji tego postu i może przestać działać w wyniku zmian na stronie. Na potrzeby przykładu sprawdzimy cenę losowo wybranego hostelu. Żeby poznać dokładną cenę oraz ile kosztowałoby odwołanie musimy:
- Przejść do strony hotelu.
- Wybrać ile łóżek potrzebujemy.
- Kliknąć przycisk i poczekać na zakończenie nawigacji żeby pojawiły się żądane informacje.
Poniższe obrazki przedstawiają te kroki.
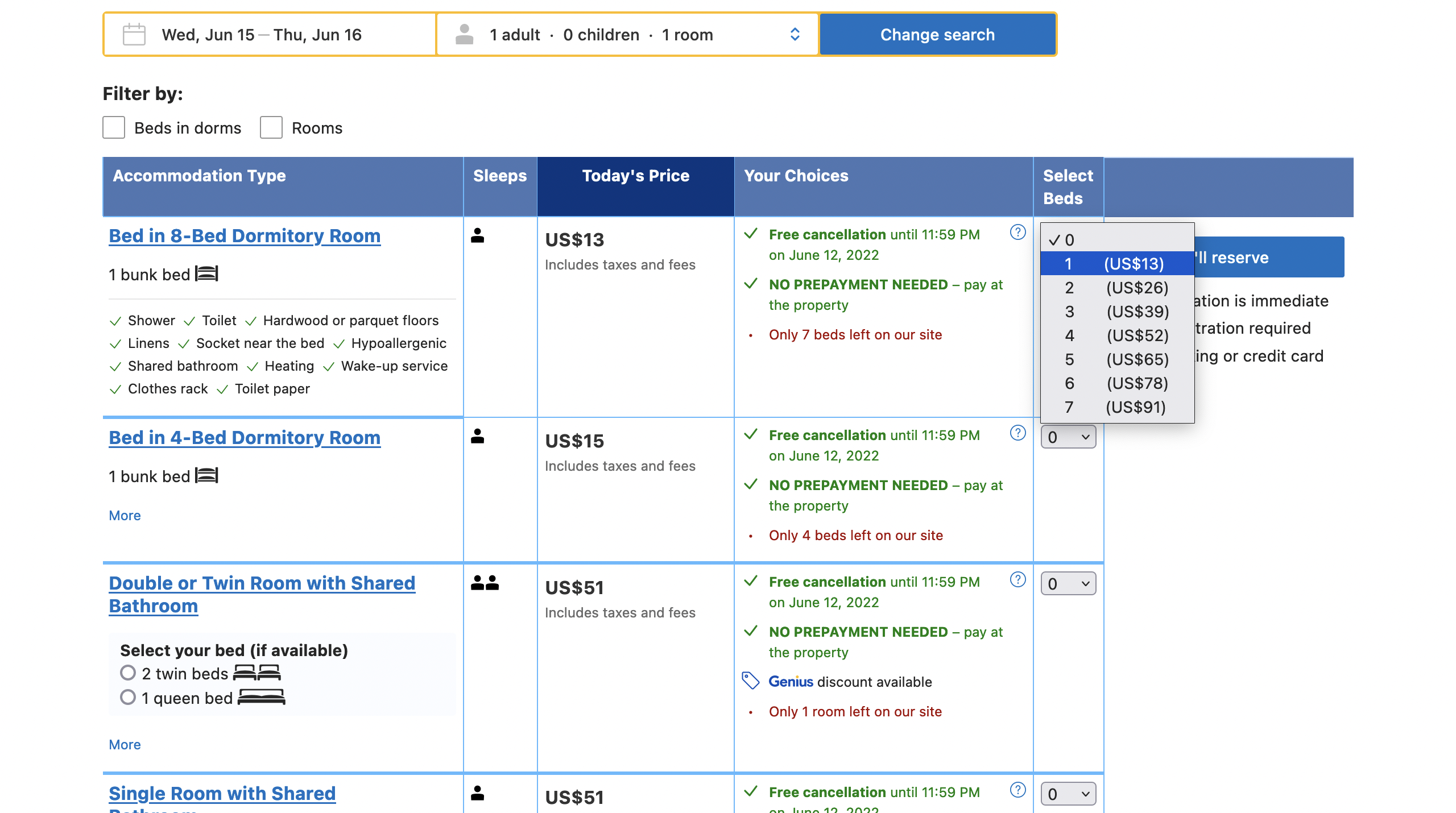
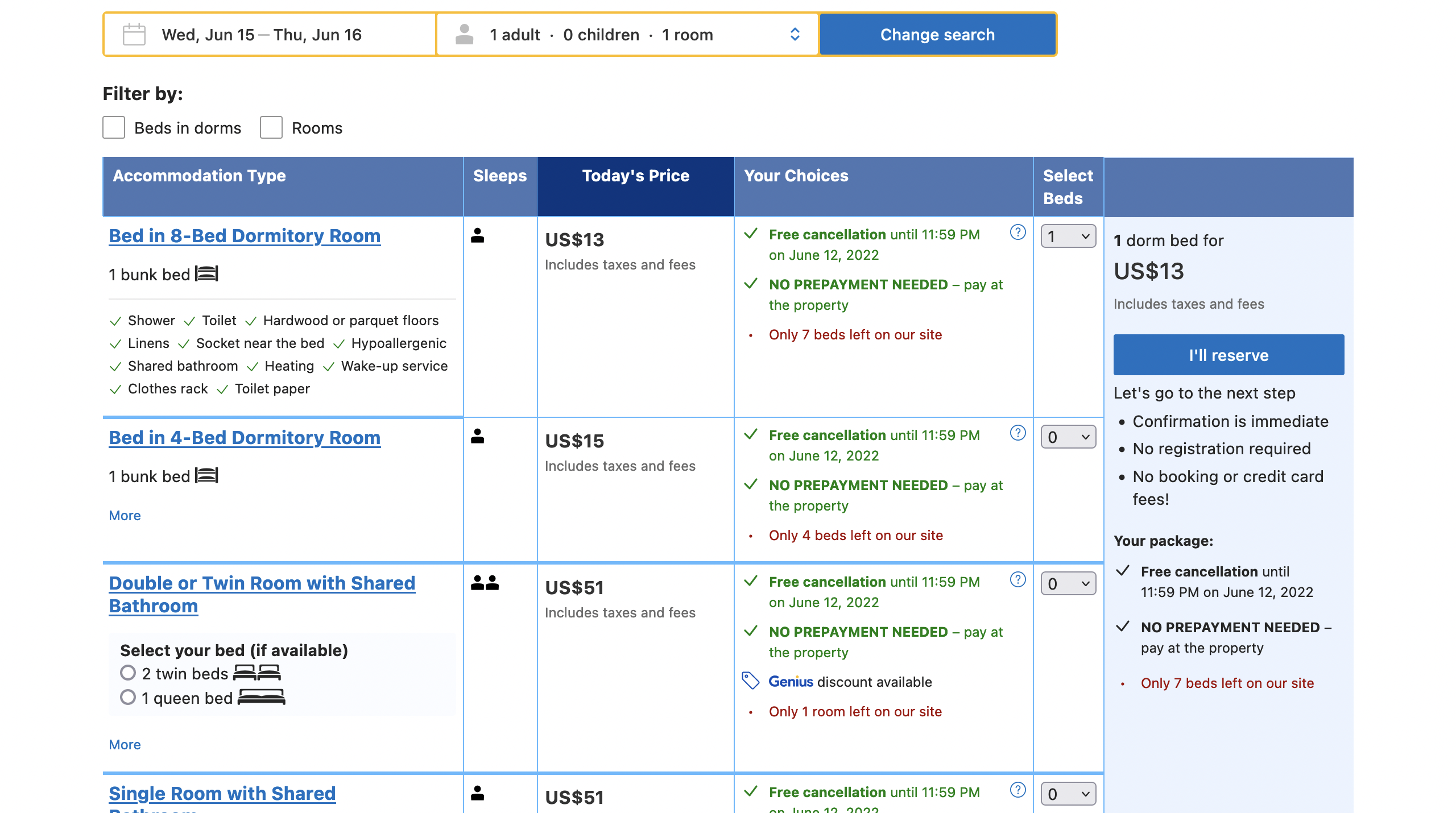
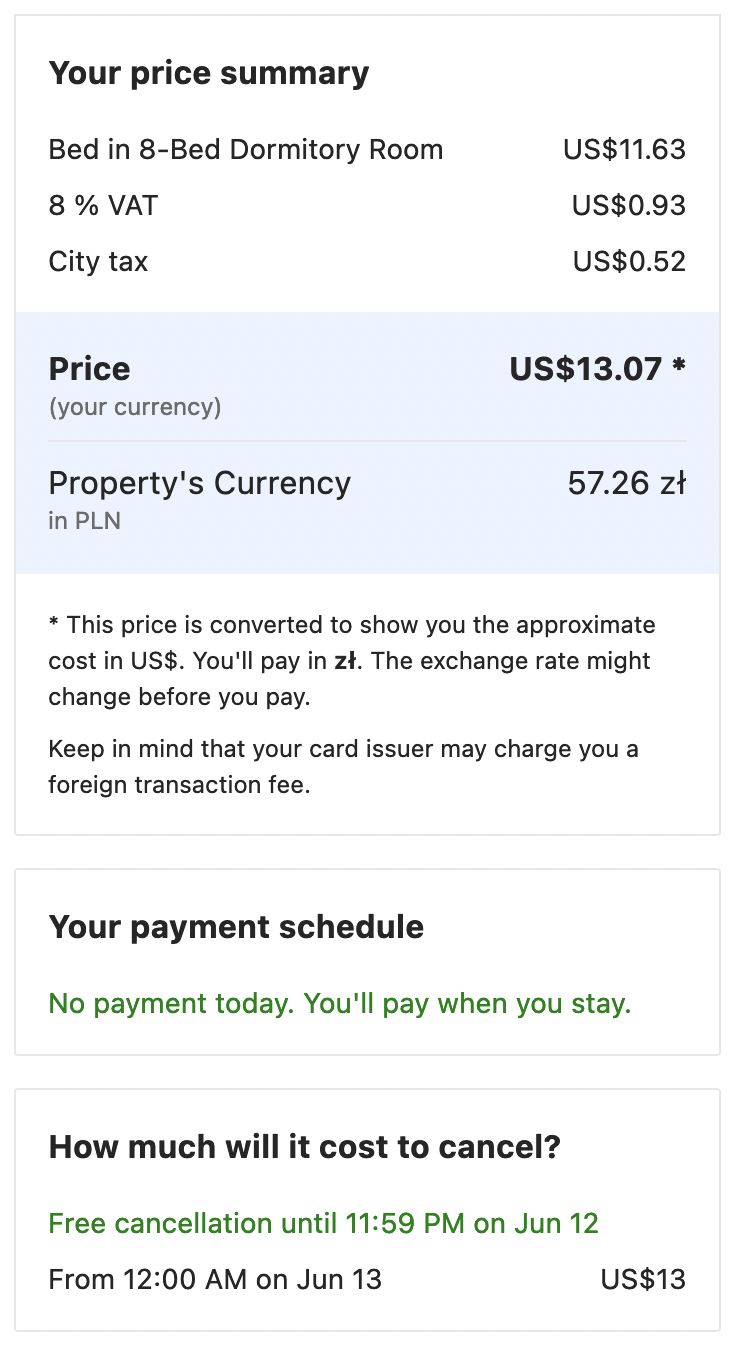
Dzięki naszej nowej funkcjonalności wszystko to można wykonać jednym requestem do API Scraping Fish.
import requests
import json
import datetime
from urllib.parse import quote_plus
checkin_date = datetime.date.today() + datetime.timedelta(30)
checkout_date = checkin_date + datetime.timedelta(1)
checkin = checkin_date.strftime("%Y-%m-%d")
checkout = checkout_date.strftime("%Y-%m-%d")
url = f"https://www.booking.com/hotel/pl/la-guitarra-hostel-gdansk.html?aid=304142&label=gen173nr-1FCAEoggI46AdIM1gEaLYBiAEBmAEeuAEHyAEP2AEB6AEB-AELiAIBqAIDuAKb8ZKUBsACAdICJDJmNDliMzMxLWIzYjEtNDQyNi1iNTdjLTljODIxNjg1M2Y3YdgCBuACAQ&sid=85334a8861a557bc4c65d6eabd08e1fe&all_sr_blocks=32277903_118755301_0_0_&checkin={checkin}&checkout={checkout}&dest_id=-501400&dest_type=city&group_adults=1&group_children=0&hapos=1&highlighted_blocks=32277903_118755301_0_0_0&hpos=1&lang=en-us&matching_block_id=32277903_118755301_0_0_0&no_rooms=1&req_adults=1&req_children=0&room1=A&sb_price_type=total&soz=1&sr_order=popularity&sr_pri_blocks=32277903_118755301_0_0_0__12452&srepoch=1652865196&srpvid=42cc40d5eaa90626&type=total&ucfs=1&lang_click=other&cdl=pl&lang_changed=1"
scenario = {
"steps": [
{"select": {"selector": "#hprt_nos_select_32277903_118755301_0_0_0", "options": "1"}},
{"click": ".txp-bui-main-pp"},
{"wait_for": ".bp-card--cancellation-schedule"}
]
}
url = quote_plus(url)
scenario = quote_plus(json.dumps(scenario))
api_key = "[your API key]"
response = requests.get(f"https://scraping.narf.ai/api/v1/?api_key={api_key}&url={url}&js_scenario={scenario}")
print(response.content)
I to wszystko! Proste jak zawsze.
Spróbuj sam!
To była szybka prezentacja przedstawiająca jak używać scenariusza JavaScript żeby pozyskać dane, których może potrzebować Twój biznes. Możliwości są nieskończone!
Zainteresowały Cię możliwości, które otwiera przed Tobą wykonywanie scenariuszy JavaScript? Możesz zacząć używać API Scraping Fish już od 8zł!